
[사이언스칼럼] 2025년, AI는 어떻게 진화했는가: 에이전트·평가·학습의 재정의
Published:
지난 1월 딥시크 R1 모델이 등장해 세상을 떠들썩하게 했다. 이 중국발 오픈소스 추론 모델은 오픈AI의 추론 모델인 o1과 견줄 만한 성능을 내며, 상대적으로 적은 비용과 알고리즘 효율화로도 최고 수준의 모델을 만들 수 있음을 보여주며 AI 산업의 판도를 뒤흔들었다. 그 충격파는 1년 내내 이어졌고, 2025년 AI는 눈부신 진화를 이루었다. 에이전트, 평가, 학습 및 스케일링의 진화라는 축에서 2025년을 되돌아보자.
첫째는 에이전트의 진화다. 3월 마누스 AI(Manus AI)의 등장은 AI 에이전트 시대의 신호탄이었다. 복잡한 작업을 자율적으로 수행하는 에이전트 개념은 새롭지 않았지만, 이를 구현하는 프레임워크들이 쏟아졌다. 랭체인, 랭그래프, 커서AI와 같은 도구들이 개발자 커뮤니티를 뜨겁게 달궜다. 이들 프레임워크는 LLM에 ‘작업 분해’, ‘도구 사용’, ‘자기 검증’ 능력을 외부에서 부여하는 방식이었다.
그러나 하반기의 풍경은 달랐다. 7월 키미 K2, 8월 GPT-5, 11월 제미나이 3가 차례로 공개되며 멀티스텝 추론과 도구 사용 등 에이전트 기능이 모델 자체에 통합되기 시작했다. 외부 프레임워크 없이도 모델 스스로 작업을 분해하고 도구를 선택하며 결과를 검증하는 능력을 갖추게 된 것이다. 에이전트가 LLM의 래퍼(wrapper)로 기능을 덧붙이는 수준을 넘어, LLM 자체의 기본 작동 방식으로 자리 잡는 구조적 전환이 일어나고 있다.
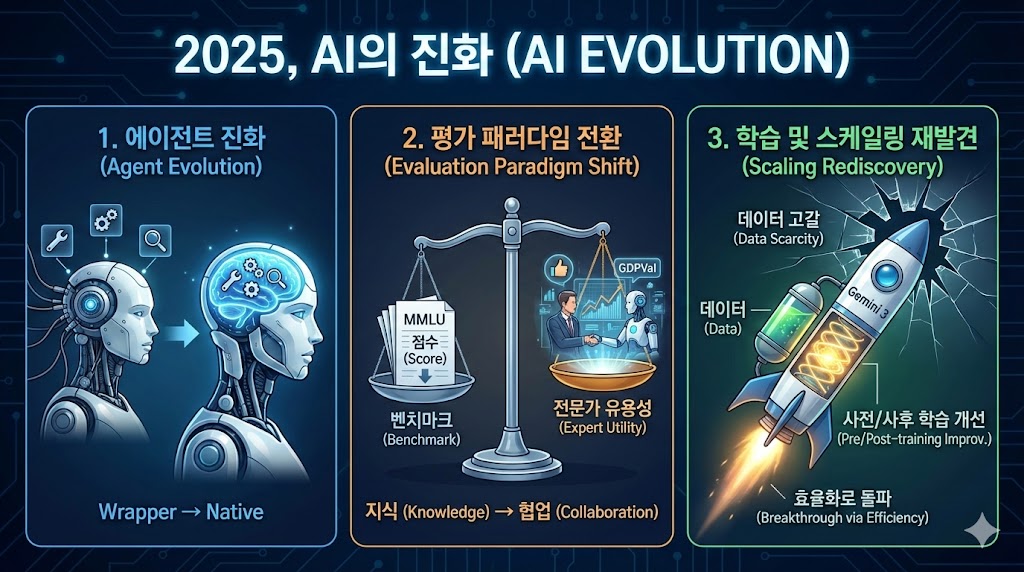
둘째는 평가 패러다임의 전환이다. 그동안 모델 경쟁은 MMLU와 같은 벤치마크 점수로 줄 세우는 식이었다. 하지만 벤치마크는 모델이 ‘무엇을 알고 있는가’를 측정할 뿐, ‘사람들에게 얼마나 유용한가’를 보여주기에는 한계가 컸다. 이 간극이 커지면서 전문가 기반 평가가 핵심 지표로 부상했다. 오픈AI의 GPT-5.1이 벤치마크보다 휴먼 평가(human eval)를 전면에 내세운 것은 상징적이다. 오픈AI가 도입한, 경제적 가치가 있는 실제 작업에 대한 모델 성능을 측정하는 새로운 평가 지표인 GDPVal은 단순한 정답률이 아니라 AI가 내놓은 결과물이 전문가의 눈높이에서 얼마나 쓸모 있는지를 본다. 기술 경쟁의 초점이 ‘누가 더 문제를 잘 맞히나’에서 ‘누가 더 인간 전문가처럼 사고하고 협업하는가’로 옮겨가고 있는 것이다.
셋째는 학습 및 스케일링 방법론의 재발견이다. 지난 10여 년은 ‘데이터와 연산량을 더 넣으면 성능은 따라온다’는 스케일링 법칙의 시대였다. 더 이상 가용한 인터넷 데이터가 없다는 고갈론과 함께 “스케일링 법칙은 끝났다”는 회의론도 나왔다. 그러나 최근 출시된 제미나이 3는 스케일링 법칙이 여전히 유효하다는 쪽에 힘을 실었다. 프로젝트를 이끈 구글 딥마인드의 오리올 비냐스는 X(구 트위터)에 “The secret behind Gemini 3?”라는 글을 올려, 비밀은 단순하지만 강력하다며 “사전학습과 사후학습 모두를 개선했다”고 밝혔다. 구체적 레시피는 밝히지 않았지만, LLM 학습 단계에서 여전히 큰 도약이 가능하다는 메시지는 분명하다.
[기사원문링크]
