International Conference on High Performance Computing in Asia-Pacific Region (HPC Asia 2021)
Published:
Held online on January 20 - 22 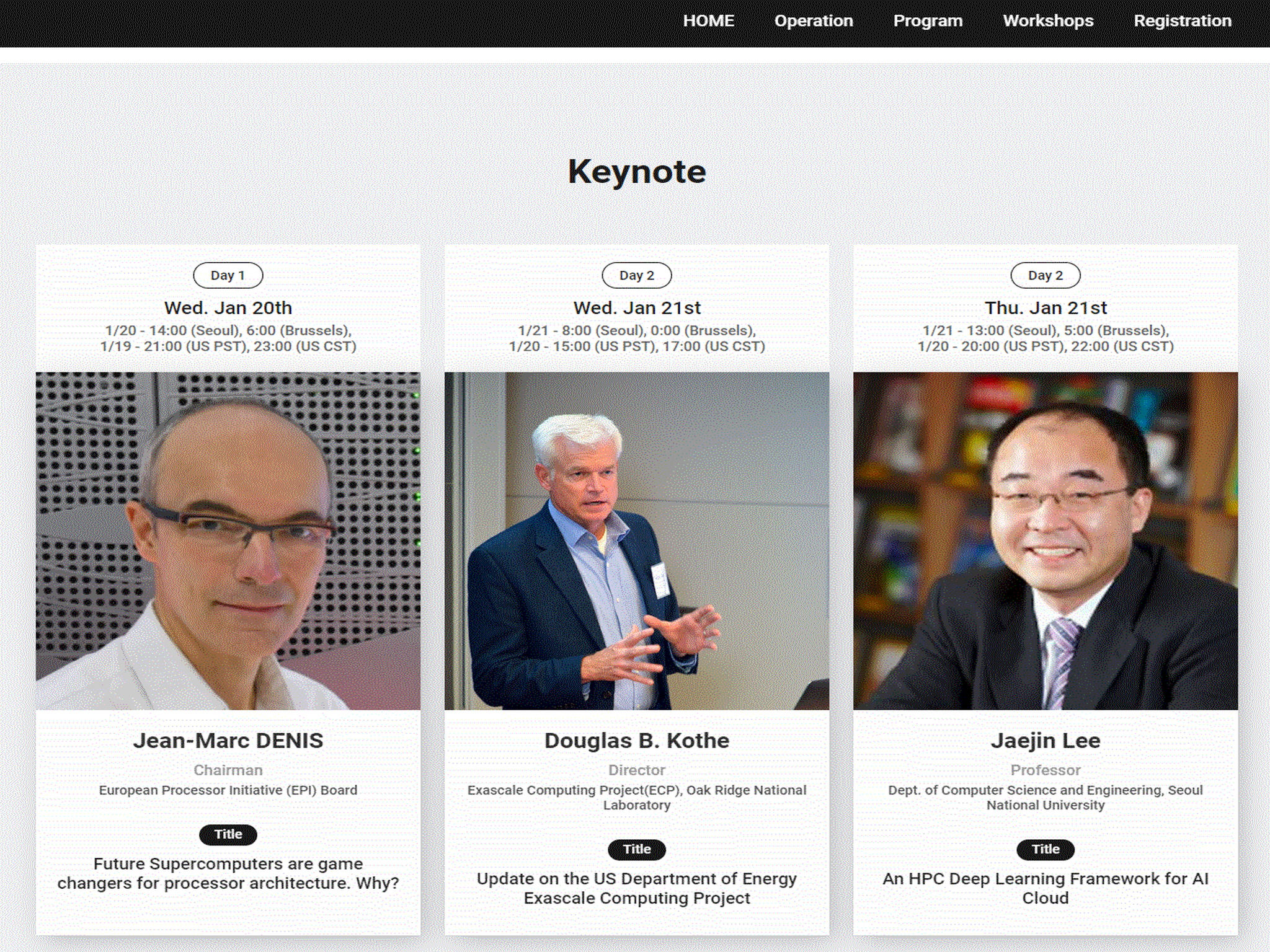

Published:
Held online on January 20 - 22
Published:
Held in Seoul National University Hoam Faculty House on July 21 
Published:
Held in Seoul Shilla Hotel on August 18 
Published:
Held in Sogang University on July 30 
Published:
Held in Sogang University on July 15 
Published:
September 2017, IEEE International Conference on Cluster Computing (CLUSTER) 
Published:
August 2023, Completion Certificate for Generative AI with Large Language Models
Published:
December 2024, Completion Certificate for Introduction to Generative AI for Software Development
Published:
December 2024, Completion Certificate for Team Software Engineering with AI
Published:
December 2024, Completion Certificate for AI-Powered Software and System Design
Published:
December 2024, Generative AI for Software Development
Published:
December 2024, AI Infrastructure and Operations Fundamentals
Published:
January 2025, Python Essentials for MLOps
Published:
January 2025, Vertex AI: Qwik Start
Published:
September 2025, Fundamentals of Accelerated Computing with Modern CUDA C++
Published in Journal 1, 2009
This paper is about the number 1. The number 2 is left for future work.
Recommended citation: Your Name, You. (2009). "Paper Title Number 1." Journal 1. 1(1).
Download Paper | Download Slides
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2).
Download Paper | Download Slides
Published in Journal 1, 2015
This paper is about the number 3. The number 4 is left for future work.
Recommended citation: Your Name, You. (2015). "Paper Title Number 3." Journal 1. 1(3).
Download Paper | Download Slides
Published in GitHub Journal of Bugs, 2024
This paper is about fixing template issue #693.
Recommended citation: Your Name, You. (2024). "Paper Title Number 3." GitHub Journal of Bugs. 1(3).
Download Paper
Published:
…My qualifications for recommending Dr. Hwang are based on my expertise as a leader in the field of Grid Computing for many years. As the founding Director of the Grid Technology Research Center (2002-2008) within the National Institute of Advanced Industrial Science and Technology (AIST), an Independent Administrative Institution under the Ministry of Economy, Trade and Industry (METI), Japan; I collaborated with Dr. Hwang in the National Research Grid Initiative (NAREGI) project in Japan from 2003. After he moved to KISTI, I continued to form a long-term partnership between AIST and KISTI, and I have interacted with Dr. Hwang on many occasions, including at HPC, AI, and high-speed networks…
Published:
…I had the opportunity to get to know Doctor Hwang when I initiated the creation of the France-Korea Particle Physics Laboratory (FKPPL) in 2007….As leader of KISTI Supercomputing/Grid/Cloud-related Research and Development Projects, Soonwook Hwang participated and gave talks regularly to European grid conferences and worshops, strengthening KISTI European collaboration and visibility. … KISTI engineers under Soonwook Hwang supervision contributed major developments to the first large scale drug discovery initiatives on international grid infrastructures. Their efforts paved the way to KISTI important contributions to the EGEE and EGI-InSPIRE European projects. Pioneering virtual screening computing experiments contributed to the identification of potential new drugs against malaria, avian flu and SRAS resulting in several patents.
Published:
…I have watched Dr. Hwang emerge as one of the world’s foremost leaders in computational science and high-performance computing (HPC). He is widely respected as a researcher in HPC, reflected not only by his publication record in international conferences and journals, but also by his participation and leadership in the global HPC community. He is one of the “go to” individuals for insights and perspectives, not only about advanced computing developments in Asia, but as a thoughtful shaper of global HPC policies and technology practices. His leadership in KISTI’s deployment of advanced computing systems has also elevated KISTI’s profile…
Published:
…I know Dr. Hwang well and have interacted with him for many years. Based on my collaboration with Dr. Hwang, I can make several observations, that all demonstrate that he is an exemplary researcher. He is very quick in assimilating new technology and insights, and bringing them to bear on established problems. He has far reaching interests, and surveys the literature widely, often coming up with very intriguing new ideas. And lastly, he is always interested in applications, and enjoys working on practical problems. Dr. Hwang combines research excellence with a deep interest in applications. … Since 2006 Dr. Hwang has been leading supercomputing development at KISTI, a distinguished national academic HPC institution worldwide. Because of his leadership KISTI has recovered a leading position in the TOP500 list for which I am an editor. The introduction of the Nurion system in 2018 was a major accomplishment for KISTI and Dr. Hwang. This system ranked #11 on the TOP500 list, which is an appropriate location for the national system of a high tech country such as South Korea…
Published:
슈퍼컴퓨터의 성능은 지속적으로 발전해서 메가, 기가, 테타,를 넘어 이제는 엑사, 즉 1초에 100경번의 연산이 가능한 “꿈의 컴퓨터”인 엑사스케일 컴퓨팅 시대가 논 앞에 다가왔습니다. 수년 전부터 미국, 중국, 일본간의 치열한 엑사스케일 컴퓨팅 경쟁을 벌여 왔습니다. 올 여름 일본이 450페타급 후가쿠 시스템을 구축하여서 엑사시스템에 한층 더 다가왔습니다. 내년이면 미국 오크리지 국립연구소에 ‘프론티어’라는 세계 최초의 엑사스케일 슈퍼컴퓨터가 구축될 예정이어서 이제 본격적으로 엑사스케일 슈퍼컴퓨팅 시대를 맞이하게 됩니다. 본 강연은 최근 글로벌 슈퍼컴퓨팅 구축 및 기술 동향과 한국의 슈퍼컴퓨팅 역사와 현황에에 대해서 조망하고자 합니다.
Published:
Distributed Deep Learning (DDL) training refers to the process of training a deep learning model on multiple machines, possibly with multiple GPUs on each machine. Not only does DDL training speed up the training process, but also enables the use of larger models and datasets that could not fit on a single GPU. This tutorial is intended to guide users to run his/her distributed deep learning codes on multiple GPU nodes using Horovod on Neuron. Neuron is a KISTI GPU cluster consisting of 65 nodes with 260 GPUs (120 of NVIDIA A100 and 140 of NVIDIA V100 GPUs). Horovod, originally developed by Uber in 2017, is a distributed deep learning framework aiming to make it easy and simple to take a DL code developed with different DL frameworks such as Tensorflow and Pytorch and scale it to run across many GPUs. This tutorial will also give a short demo of how to practice large-scale distributed deep learning training using Horovod on Perlmutter, the world 9th fastest supercomptuer, which is located at NERSC supercomputing center in Lawrence Berkeley National Laboratory.
Published:
Distributed deep learning (DDL) training refers to the process of training a deep learning model on multiple machines, possibly with multiple GPUs on each machine. Not only does DDL training speed up the training process, but also enables the use of larger models and datasets that could not fit on a single GPU. This tutorial is intended to guide users to run his/her distributed deep learning codes on multiple GPU nodes using Horovod on Neuron. Neuron is a KISTI GPU cluster consisting of 65 nodes with 260 GPUs (120 of NVIDIA A100 and 140 of NVIDIA V100 GPUs). Horovod, originally developed by Uber in 2017, is a distributed deep learning framework aiming to make it easy and simple to take a DL code developed with different DL frameworks such as Tensorflow and Pytorch and scale it to run across many GPUs.
Published:
Distributed deep learning (DDL) training refers to the process of training a deep learning model on multiple machines, possibly with multiple GPUs on each machine. Not only does DDL training speed up the training process, but also enables the use of larger models and datasets that could not fit on a single GPU. This tutorial is intended to guide users to run his/her distributed deep learning codes on multiple GPU nodes using Horovod on Neuron. Neuron is a KISTI GPU cluster consisting of 65 nodes with 260 GPUs (120 of NVIDIA A100 and 140 of NVIDIA V100 GPUs). Horovod, originally developed by Uber in 2017, is a distributed deep learning framework aiming to make it easy and simple to take a DL code developed with different DL frameworks such as Tensorflow and Pytorch and scale it to run across many GPUs. This tutorial will also give a short demo of how to practice large-scale distributed deep learning training using Horovod on Perlmutter, the world 9th fastest supercomptuer, which is located at NERSC supercomputing center in Lawrence Berkeley National Laboratory.
Published:
Distributed deep learning (DDL) training refers to the process of training a deep learning model on multiple machines, possibly with multiple GPUs on each machine. Not only does DDL training speed up the training process, but also enables the use of larger models and datasets that could not fit on a single GPU. This talk is intended to introduce the principles, concepts and approaches of large-scale distributed DL practices on a supercomputer, and guide users to run his/her distributed deep learning codes on multiple GPU nodes using Horovod on Neuron. Neuron is a KISTI GPU cluster consisting of 65 nodes with 260 GPUs (120 of NVIDIA A100 and 140 of NVIDIA V100 GPUs). Horovod, originally developed by Uber in 2017, is a distributed deep learning framework aiming to make it easy and simple to take a DL code developed with different DL frameworks such as Tensorflow and Pytorch and scale it to run across many GPUs.
Published:
Distributed deep learning (DDL) training refers to the process of training a deep learning model on multiple machines, possibly with multiple GPUs on each machine. Not only does DDL training speed up the training process, but also enables the use of larger models and datasets that could not fit on a single GPU. This talk is intended to introduce the principles, concepts and approaches of large-scale distributed DL practices on a supercomputer, and guide users to run his/her distributed deep learning codes on multiple GPU nodes using Horovod on Neuron. Neuron is a KISTI GPU cluster consisting of 65 nodes with 260 GPUs (120 of NVIDIA A100 and 140 of NVIDIA V100 GPUs). Horovod, originally developed by Uber in 2017, is a distributed deep learning framework aiming to make it easy and simple to take a DL code developed with different DL frameworks such as Tensorflow and Pytorch and scale it to run across many GPUs. This talk will also give a short demo of how to practice large-scale distributed deep learning training using Horovod on Perlmutter, the world 9th fastest supercomptuer, which is located at NERSC supercomputing center in Lawrence Berkeley National Laboratory.
Published:
Distributed deep learning (DDL) training refers to the process of training a deep learning model on multiple machines, possibly with multiple GPUs on each machine. Not only does DDL training speed up the training process, but also enables the use of larger models and datasets that could not fit on a single GPU. This tutorial is intended to share best practices for large-scale distributed training on a supercomputer, guiding users on how to run their distributed deep learning codes on multiple GPU nodes using Horovod on Neuron. The Neuron system is a KISTI GPU cluster consisting of 65 nodes with 260 GPUs (120 of NVIDIA A100 and 140 of NVIDIA V100 GPUs). Horovod, originally developed by Uber in 2017, is a distributed deep learning framework aiming to make it easy and simple to take a DL code developed with different DL frameworks such as Tensorflow and Pytorch and scale it to run across many GPUs. This tutorial will also give a short demo of how to practice large-scale distributed deep learning training using Horovod on Perlmutter, the world 9th fastest supercomptuer, which is located at NERSC supercomputing center in Lawrence Berkeley National Laboratory.
Published:
최근에 구축되는 Top10 슈퍼컴퓨터들은 한 노드에 최신 GPU 4~8개를 장착하고 있다. 본 세션에서는 슈퍼컴퓨터에서의 멀티 GPU노드를 활용한 대규모 분산딥러닝하기 Best Practices를 소개한다. (1)슈퍼컴퓨터에 접속해서 (2)각자의 가상 환경을 만들고 (3)온라인으로 GPU 1~2개를 할당받아 터미널 또는 주피터 환경에서 분산딥러닝 코드를 개발 및 테스트 한 후에 (4)배치 작업을 통해서 대규모 분산딥러닝 작업을 실행하는 슈퍼컴퓨터에서의 AI/DL 연구프로세스에 대해서 공유하고 의견을 나누고자 한다.
Published:
Generative AI with LLMs refers to the use of large language models like GPT-3 for generating human-like content, spanning text, images and even code. LLMs are trained on a vast amount of data and code, and usually carefully prompt-engineered or fine-tuned to suit specific downstream tasks such as Chatbots, Translation, Question Answering and Summarization. The contents and python codes of this tutorial are originated from the 16-hour “Generative AI with LLMs” course offered by the DeepLearning.AI. This tutorial will mainly cover the key concepts and practices of a typical LLM-powered Generative AI lifecycle, from data gathering and model selection, to instruction fine-tuning and RLHF-based alignment to human preference, to performance evaluation and deployment. For hands-on exercises, students will have access to the KISTI GPU cluster known as Neuron, which consists of 65 nodes with 260 GPUs (120 of NVIDIA A100 and 140 of NVIDIA V100 GPUs) running SLURM as for its workload manager.
Published:
Generative AI with LLMs refers to the use of large language models like GPT-3 for generating human-like content, spanning text, images and even code. LLMs are trained on a vast amount of data and code, and usually carefully prompt-engineered or fine-tuned to suit specific downstream tasks such as Chatbots, Translation, Question Answering and Summarization. The contents and python codes of this seminar are mainly originated from the 16-hour “Generative AI with LLMs” course offered by the DeepLearning.AI. This talk will cover the key concepts and practices of a typical LLM-powered Generative AI lifecycle, from data gathering and model selection, to instruction fine-tuning and RLHF-based alignment to human preference, to performance evaluation and deployment. I will show a short demo on how users can create a conda virtual environment on the KISTI Neuron cluster with 260 GPUs, launch a Jupyter server on a compute node and have access it to from his/her own PC or Labtop for Genera tive AI practices on a supercomputer. The demo will illustrate how to conduct LLM practices including prompting and prompt engineering, and instruction fine-tuning and parameter-efficient fine-tuning (PEFT) with LoRA, and evaluation and benchmark on LLMs.
Published:
Generative AI with LLMs refers to the use of large language models like GPT-3 for generating human-like content, spanning text, images and even code. LLMs are trained on a vast amount of data and code, and usually carefully prompt-engineered or fine-tuned to suit specific downstream tasks such as Chatbots, Translation, Question Answering and Summarization. The contents and python codes of this seminar are mainly originated from the 16-hour “Generative AI with LLMs” course offered by the DeepLearning.AI. This talk will cover the key concepts and practices of a typical LLM-powered Generative AI lifecycle, from data gathering and model selection, to instruction fine-tuning and RLHF-based alignment to human preference, to performance evaluation and deployment. I will show a short demo on how users can create a conda virtual environment on the KISTI Neuron cluster with 260 GPUs, launch a Jupyter server on a compute node and have access it to from his/her own PC or Labtop for Genera tive AI practices on a supercomputer. The demo will illustrate how to conduct LLM practices including prompting and prompt engineering, and instruction fine-tuning and parameter-efficient fine-tuning (PEFT) with LoRA, and evaluation and benchmark on LLMs.
Published:
Generative AI with LLMs refers to the use of large language models like GPT-3 for generating human-like content, spanning text, images and even code. LLMs are trained on a vast amount of data and code, and usually carefully prompt-engineered or fine-tuned to suit specific downstream tasks such as Chatbots, Translation, Question Answering and Summarization. The contents and python codes of this tutorial are originated from the 16-hour “Generative AI with LLMs” course offered by the DeepLearning.AI. This tutorial will mainly cover the key concepts and practices of a typical LLM-powered Generative AI lifecycle, from data gathering and model selection, to instruction fine-tuning and RLHF-based alignment to human preference, to performance evaluation and deployment. For hands-on exercises, students will have access to the KISTI GPU cluster known as Neuron, which consists of 65 nodes with 260 GPUs (120 of NVIDIA A100 and 140 of NVIDIA V100 GPUs) running SLURM as for its workload manager.
Published:
본 세션에서는 슈퍼컴퓨터에서 “LLM 기반 생성형 AI 해보기”의 Best Practice를 소개합니다. 데이터 수집, 모델 선택, 프롬프트 엔지니어링, 인스트럭션 파인튜닝, 평가 및 벤치마킹 등 생성형 AI 프로젝트 라이프사이클 전 과정을 살펴보고, KISTI GPU 클러스터에 접속해서 시연을 진행합니다. 특히, 슈퍼컴퓨터와 AWS 같은 클라우드 플랫폼 환경을 비교하고, SLURM 기반슈퍼컴퓨터 환경에서 주피터 노트북을 활용한 생성형 AI 실습 사례를 공유합니다.
Published:
In this talk, I present an overview of the evolving landscape of Large Language Models (LLMs), tracing their progression from the introduction of the Transformer in 2017 to the latest developments like DeepSeek-R1 in 2025. The talk reflects on this evolution, particularly in terms of the types of training datasets and approaches, including pretraining, Supervised/Instruction Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF). It also delves into the rise of Agentic AI during 2025, featuring key technologies such as Manus AI and Model Context Protocol (MCP). The presentation includes hands-on demonstrations showcasing the creation of basic AI agents using GPTs, Claude+MCP, and n8n.
Published:
In this talk, I present an overview of the evolving landscape of Large Language Models (LLMs), tracing their progression from the introduction of the Transformer in 2017 to the latest developments like DeepSeek-R1 in 2025. The talk reflects on this evolution, particularly in terms of the types of training datasets and approaches, including pretraining, Supervised/Instruction Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF). It also delves into the rise of Agentic AI during 2025, featuring key technologies such as Manus AI and Model Context Protocol (MCP). The presentation includes hands-on demonstrations showcasing the creation of basic AI agents using GPTs, Claude+MCP, and n8n.
Published:
In this talk, I present an overview of the evolving landscape of Large Language Models (LLMs), tracing their progression from the introduction of the Transformer in 2017 to the latest developments like DeepSeek-R1 in 2025. The talk reflects on this evolution, particularly in terms of the types of training datasets and approaches, including pretraining, Supervised/Instruction Fine-Tuning (SFT), and Reinforcement Learning from Human Feedback (RLHF). It also delves into the rise of Agentic AI during 2025, featuring key technologies such as Manus AI and Model Context Protocol (MCP). The presentation includes hands-on demonstrations showcasing the creation of basic AI agents using GPTs, Claude+MCP, and n8n.
Published:
This tutorial presents a comprehensive, in-depth guide for large-scale distributed training of LLMs on supercomputers managed with SLURM. It briefly covers some basics of collective communications in message passing including gather, scatter and all-gather operations, delving into data parallelism techniques such as Data Parallelism (DP) and Distributed Data Parallelism (DDP) in PyTorch, and model parallelism techniques including Tensor Parallelism, Pipeline Parallelism, and 3D Parallelism, with hands-on PyTorch code examples. It also covers how to set up and leverage distributed training tools like NVIDIA Megatron-LM and Microsoft DeepSpeed to efficiently run the PyTorch codes using multiple GPUs on a supercomputer.
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.